



Web site owner hide their webpages using commands in Robots.txt.Robots.txt is a text file which is located in the root directory of a site.It is used to control webpages indexed by a robot,ie. you can disallow a particular web page or content to be spidered from search engine robots. By using ‘disallow‘ word you can block any URL of your blog from reaching search engines.
We will take the help of Robots.text file to see the hidden web site pages and content
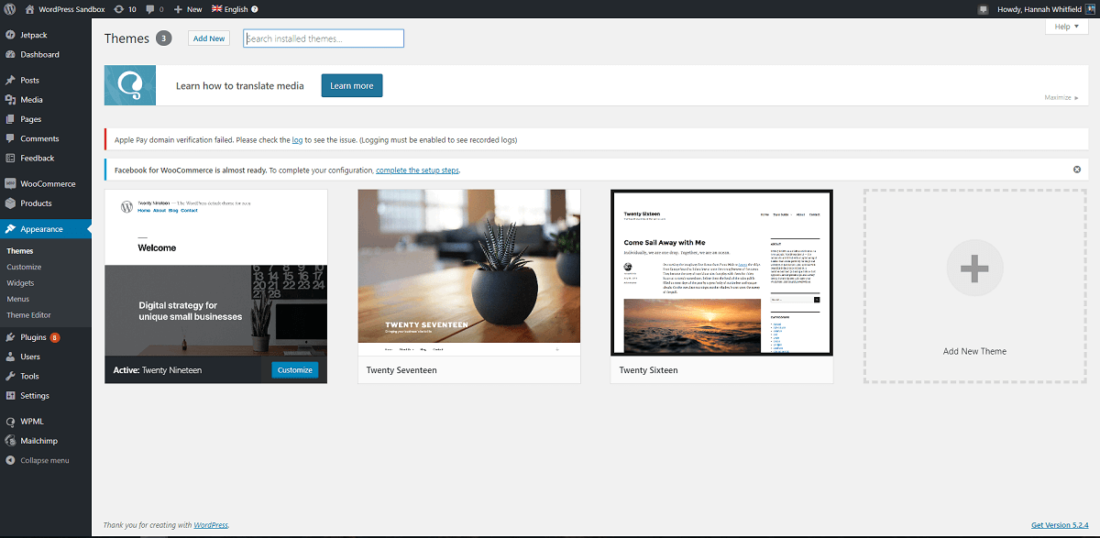
Step 1 – Go to Google and type this in the search box
“robots.txt” “disallow:” filetype:txt
Hit enter and you will be presented with loads of Robots file website results which have a disallow command.
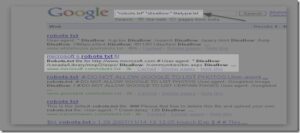
Step 2 – From thousands of results we will choose any website,for example I will open Microsoft robot text file which is in the 1st page (Highlighted).After opening the robot text file,it looks like this
These are the content and pages which Microsoft doesn’t want search engine spider to get indexed.Now copy any line after the word Disallow:
For example we will copy this line :
/communities/blogs/PortalResults.mspx
Remember to copy the slash which is at the beginning of the line.
Step 3 – Type the main website url and then the line which you have copied in the Step 2
![]()
After combining both the main website URL and the line,Hit enter (See the screenshot)
Main url – http://microsoft.com
Line – /communities/blogs/PortalResults.mspx
Combination – http://www.microsoft.com/communities/blogs/PortalResults.mspx
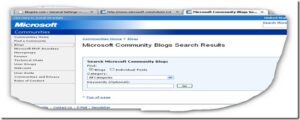
This was the page Microsoft had hidden from the search engine!
This was just an example,you can find some more interesting web pages and other secret content easily.Go ahead and try !